1장 데이터 시빌라이저 구조

Data Civilizer의 개념적인 동작 구조를 그림으로 간단하게 표현했구요. 이 그림은 Data Civilizer논문을 인용했고, 간단하게 설명을 해보도록 하죠.
설명하기 전에 앞으로 Data Civilizer(데이터 시빌라이저)는 한글로 “데이터 시빌라이저”로 칭하도록 할게요. (한국인은 역시 한글을 써야죠)
데이터 시빌라이저는 Online과 Offline 두 영역으로 나누어져 있는 구조를 갖고 있어요.
Online영역은 사용자에게 직접 마주하고 있는 검색 모듈(Discovery)가 위치하고 있으며, Offline 영역에서는 시간이 오래걸리는 방대한 양의 데이터를 정리하고, 프로파일링을 통해 링크 그래프로 작성하는 것을 담당하고 있어요.
그림에서 우측에 있는 Workflow Orchestrator은 현재 구현 되어있는 것이 아니라, 앞으로 구현할 것이고 이 아이디어는 성공적일 것이다 라고 제시하고 있는데…! 결론은 구현해봐야 성공인지 실패인지 알게 되겠죠?
2장 링크 그래프

1장 데이터 시빌라이저 구조에서 간략하게 설명한 것처럼 Offline 영역에서 링크그래프를 만들어놓게 됩니다.
링크그래프를 만드는데 카디널리티, 중복, 무결성을 기준으로 데이터 클리닝 작업과 프로파일링 작업을 수행을 하게 됩니다.
데이터 시빌라이저의 링크 그래프는 하이퍼그래프로 모델링하여 생성하고 있습니다.
|
※ 하이퍼그래프(HyperGraph)란 ? 한 엣지(edge)에 여러 노드(node)가 동시에 연결된 네트워크가 있습니다. 개개인을 한 노드로 하는 거대한 사회 연결망(social network)을 구축했을 때 여러 가족을 표현할 때를 예로 들 수 있습니다. 가족에는 2명 이상의 개개인이 속하게 되는데, 이 때 가족이라는 한 엣지로 2개 이상의 노드가 연결되는 것입니다. |
3장 검색 모듈
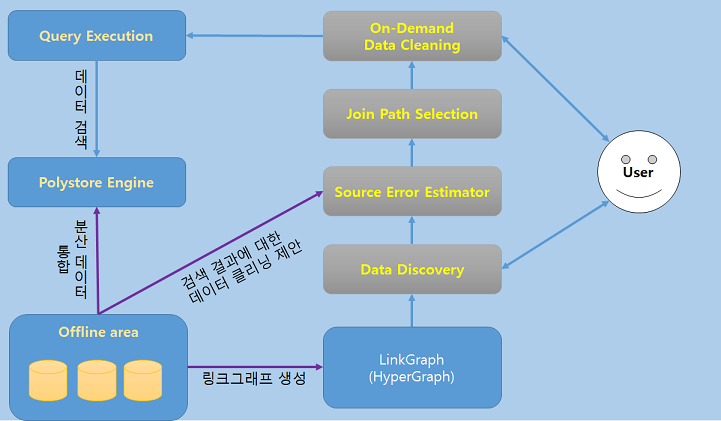
사용자는 데이터 검색을 요청했을 때, 검색 모듈(Data Discovery)은 Offline에서 미리 만들어놓은 링크 그래프를 참조해서 관련 데이터를 얻어 사용자에게 보여주게 됩니다. 그리고 결과를 가져올 때, Source Error Estimator과 Join Path Selection을 통해서 해당 데이터 클리닝을 제안하게 됩니다.
사용자는 제공받은 결과가 원하는 성능의 데이터가 아닌 경우, 제안 받은 데이터 클리닝을 Online 영역에서 진행하고, 클리닝한 데이터를 다시 제공받을 수 있습니다.
Online 영역에서 데이터 클리닝을 진행할 때는 Query Execution 에서 쿼리를 통해 Polystore Engine 에서 Polystore를 진행합니다.
데이터 시빌라이저 개념을 다루는 이 논문에서는 Polystore 를 Rheem 또는 BIGDWAG 사용할 수 있다고 소개되었지만, 실제 데모에서는 Rheem 을 활용해서 Polystore를 구현하고 있습니다.

|
※ 폴리스토어(Polystore)란 ?
분산 되어있는 데이터베이스 엔진을 하나의 데이터베이스처럼 통합 검색할 수 있도록 지원해주는 기능입니다. |
4장 데이터 업데이트
데이터를 주기적으로 수집하게 되면 새로운 데이터에 대해서 링크그래프에 적용하기 위해 업데이트를 해야할 필요성이 있게 됩니다. 데이터 시빌라이저에서 업데이트 전략은 3가지가 있는데 1) MV 유지보수, 2) 데이터 관리, 3) 그래프 업데이트를 수행합니다.
MV 유지보수는 QCRI와 Waterloo에서 개발한 DBRx 기법을 사용합니다. 이 기법을 사용해서 자동으로 수행했을 때 실패한 경우, 사용자가 직접 수동으로 작업을 진행할 수 있습니다. 하지만 두 작업 모두 실패한 경우에는 해당 MV를 폐기하게 됩니다.
데이터 관리는 새로운 데이터가 수집되어 다른 데이터 세트에 영향이 있을 수 있기 때문에 업데이트된 것을 전파하기 위해서 데이터 세트간의 관계를 추적할 수 있어야한다. 추척은 MIT에서 개발한 Decibel 기술을 사용합니다.
그래프 업데이트는 새로운 데이터가 수집될 때마다 업데이트를 수행할 경우, 성능의 저하가 올 수 있기 때문에 업데이트를 진행할 추정치 임계 값을 설정하고, 새로 업데이트된 데이터 열의 추정치가 설정된 임계 값을 초과할 때 업데이트가 진행됩니다.
5장 워크플로우
사용자가 어떠한 데이터 클리닝 작업을 진행할 것인지 작업 순서들을 지정할 수 있습니다. 이 작업 순서를 워크플로우 형태로 여러 개 만들어 놓을 수 있도록 합니다.
여기서 사용자가 만들어놓은 워크플로우를 가지고 좀 더 좋은 성능을 보여줄 수 있는 워크플로우를 제안하고 성능 평가를 해주는 기능이 있으면 성공적인 기능이 될 것이라고 아이디어를 제시하고 있습니다.
다시 말해서, Workflow Orchestrator를 통해서 기존의 워크플로우를 기억하고 있다가, 사용자가 검색 모듈을 통해 검색했을 때, 해당 데이터의 성능 평가를 해주고 좀 더 좋은 성능을 할 수 있는 워크플로우를 제안할 수 있는 기능을 제안하고 있습니다.
* 영어 논문이다보니 오역이 있을 수 있으며, 제가 잘못 이해한 부분이 있다면 댓글 남겨주시면 수정하도록 하겠습니다.


댓글